Kafka 数据入湖新范式 告别传统 ETL 的数据处理与存储革命
在数据驱动的时代,企业面临着海量实时数据的高效处理与价值挖掘挑战。传统的数据处理流程,尤其是基于批处理的 ETL(抽取、转换、加载)模式,因其固有的延迟、复杂性和资源消耗,已难以满足现代业务对实时性、灵活性和成本效益的迫切需求。随着数据湖架构的普及和流处理技术的成熟,一种以 Apache Kafka 为核心的数据入湖新范式正在兴起,它正在重新定义数据处理与存储的边界,引领我们告别传统的 ETL 范式。
传统 ETL 的桎梏
传统的 ETL 流程通常是一个周期性、批量的作业。数据从源系统被抽取出来,经过集中式的转换处理,最后加载到数据仓库或其它存储系统中。这一模式存在几个显著痛点:
- 高延迟:批量处理意味着数据从产生到可用存在数小时甚至数天的延迟,无法支持实时决策与即时响应。
- 架构复杂:ETL 管道往往由多个独立、紧耦合的组件构成,开发、运维和变更成本高昂。
- 灵活性差:模式(Schema)变更困难,难以适应快速变化的业务需求。数据处理逻辑一旦固化,调整起来耗时费力。
- 资源浪费:在数据量激增的背景下,周期性全量处理或复杂的增量逻辑可能导致计算与存储资源的低效利用。
Kafka 数据入湖新范式的核心理念
新范式以 Apache Kafka 作为实时数据中枢和流式数据平台,构建了一条通往数据湖的“高速公路”。其核心转变在于:从“先存储,后处理”的批处理思维,转向“流式优先,实时入湖”的架构。
核心组件与流程:
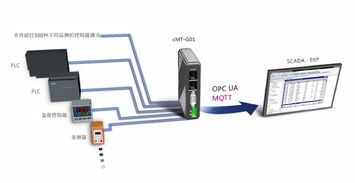
1. Kafka 作为统一数据入口:所有源头系统的变更数据(CDC)、应用程序日志、物联网设备数据、用户行为事件等,都以流的形式实时摄入 Kafka。Kafka 在此扮演了高吞吐、低延迟、持久化的缓冲区和分发中心角色。
2. 流式处理与轻量转换:利用 Kafka Streams、ksqlDB 或 Flink 等流处理框架,在数据流动的过程中进行实时的清洗、过滤、富化、聚合等轻量级转换。这与传统 ETL 中繁重的、批量的转换形成鲜明对比。
3. 直接、持续地流入数据湖:经过初步处理的数据流,通过 Connector(如 Kafka Connect 的 HDFS/S3 Connector)或流处理作业本身,以微批或连续的方式直接写入数据湖(如 Amazon S3、Azure Data Lake Storage、HDFS)。数据以原始或近原始格式(如 Avro、Parquet)存储,保留了最大的灵活性与保真度。
4. 湖仓一体与后期分析:数据湖成为所有数据的单一事实来源。在此基础上,可以通过 Presto、Trino、Spark 或云上数据仓库(如 Snowflake、BigQuery)进行灵活的即席查询、批处理分析或机器学习。元数据管理(如 Apache Hudi、Delta Lake、Iceberg)确保了数据湖中数据的ACID特性和高效管理。
新范式的优势
- 极致的实时性:数据从产生到入湖可供分析,延迟可降至秒级甚至亚秒级,真正实现了实时数据湖。
- 架构解耦与弹性:Kafka 将数据生产者与消费者解耦,数据入湖与下游消费(如数据分析、机器学习)成为独立的、可扩展的环节。系统各组件可以独立伸缩。
- 简化数据处理流水线:“流式ETL”或“ELT”(先加载后转换)模式简化了管道。许多转换可以在流中实时完成,更复杂的转换可以移至数据湖上的计算引擎按需执行。
- 成本效益与灵活性:数据湖存储成本相对低廉,且支持存储任意格式的数据。原始数据的保留使得后续可以反复挖掘,无需回溯复杂的ETL流程。
- 更好的数据治理与可观测性:Kafka 提供了完整的数据流转轨迹和监控指标,结合数据湖的元数据层,整个数据生命周期的可观测性和治理能力得到增强。
实践与展望
这一范式已被众多互联网和数字化转型企业所采用。例如,将数据库的CDC日志通过 Debezium 接入 Kafka,实时同步至 S3 形成数据湖,并立即用于实时报表、风险监控或特征工程。
Kafka 数据入湖新范式将与云原生、Serverless 计算更深度结合。数据湖与数据仓库的边界将进一步模糊(湖仓一体),而 Kafka 作为实时数据流的核心地位将更加稳固。它不仅仅是一个消息队列,更是构建现代数据架构的基石。
****
告别传统的、笨重的 ETL,并不意味着放弃数据处理的原则,而是拥抱一种更敏捷、更实时、更经济的实践。Kafka 引领的数据入湖新范式,通过将数据流动起来,释放了数据的即时价值,为企业在数据洪流中保持竞争力提供了强大的架构支撑。这不仅仅是一次技术迭代,更是一次面向未来的数据处理哲学转变。
如若转载,请注明出处:http://www.lqcg88.com/product/52.html
更新时间:2026-06-19 21:13:45