构建基于MySQL与Redis的统一KV存储服务 架构设计与实践
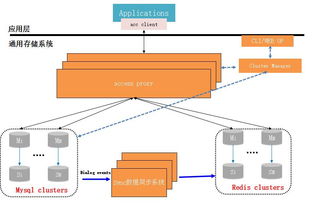
在当今数据驱动的应用场景中,KV(Key-Value)存储服务因其高效、灵活的特性而被广泛采用。单一的存储引擎往往难以满足所有业务需求。本文将探讨如何结合MySQL的关系型数据管理能力与Redis的高性能内存存储,构建一个统一、可靠且高效的KV存储服务。
一、架构设计核心理念
统一KV存储服务的核心在于分层存储与智能路由。我们将数据按访问模式分层:
- 热数据(高频访问):存储在Redis中,利用其内存读写优势,提供亚毫秒级响应。
- 冷数据/全量数据:存储在MySQL中,作为持久化层,确保数据的可靠性与一致性。
架构组件包括:
- 统一访问层(Gateway):接收客户端请求,根据Key进行路由决策。
- 缓存层(Redis):集群部署,采用主从复制与哨兵模式(或Redis Cluster)保障高可用。
- 持久层(MySQL):采用分库分表策略(如基于Key哈希),支持水平扩展。
- 数据同步组件:实现MySQL与Redis之间的数据一致性同步。
二、关键技术实现
- 路由策略:在Gateway中维护路由表或使用一致性哈希算法,将Key映射到对应的Redis或MySQL节点。对于写操作,可先写入MySQL,再异步更新Redis;对于读操作,优先查询Redis,若未命中则穿透至MySQL并回填Redis。
- 数据同步机制:
- 写操作:采用双写策略,客户端同时写入MySQL和Redis(或先写MySQL,通过Binlog监听异步更新Redis)。为减少延迟,可引入消息队列(如Kafka)解耦。
- 数据一致性:通过版本号或时间戳解决并发冲突。对于强一致性场景,可使用分布式锁(如基于Redis的RedLock)保证原子性。
- 缓存失效:设置合理的TTL,并结合主动淘汰策略(如LRU)。当MySQL数据更新时,通过触发器或监听Binlog(如使用Canal)来失效或更新Redis中的对应Key。
- 容灾与扩展:
- Redis层:采用集群模式,分片存储数据,并配置持久化(AOF/RDB)防止内存数据丢失。
- MySQL层:使用主从复制,读写分离提升吞吐量。对于海量数据,可借助中间件(如MyCat或ShardingSphere)实现自动分片。
- 服务降级:当Redis故障时,Gateway可自动降级,直接访问MySQL,保障服务可用性。
三、数据处理流程示例
以用户信息存储为例:
- 写入:客户端调用
set(user<em>id, user</em>info),Gateway将数据写入MySQL主库,并异步推送至消息队列;消费者从队列读取数据,更新Redis缓存。 - 读取:客户端调用
get(user_id),Gateway优先查询Redis。若命中则返回;若未命中,则查询MySQL从库,将结果回填至Redis并设置TTL。
四、优化与监控
- 性能优化:
- Redis使用Pipeline减少网络往返,MySQL通过索引优化查询速度。
- 针对热点Key,在Redis端采用多副本分散压力。
- 监控指标:实时追踪Redis命中率、MySQL查询延迟、同步队列堆积情况等,并设置告警阈值。
五、挑战与注意事项
- 数据一致性:在最终一致性模型下,需权衡业务对旧数据的容忍度。
- 成本控制:Redis内存成本较高,需通过数据冷热分离与压缩算法(如Snappy)降低开销。
- 复杂性管理:引入多组件后,运维复杂度增加,需借助容器化(Docker/K8s)与自动化脚本提升管理效率。
基于MySQL与Redis的统一KV存储服务,通过分层设计充分发挥了各自优势,既保证了数据持久性,又提供了高性能访问。在实际落地中,需根据业务特点灵活调整架构细节,并持续优化以实现稳定、可扩展的数据服务。
如若转载,请注明出处:http://www.lqcg88.com/product/60.html
更新时间:2026-06-19 05:04:05