MySQL索引为何选择B+树作为数据存储结构?
在关系型数据库管理系统如MySQL中,索引是提升数据查询效率的关键组件。而B+树(B-Tree的变种)被广泛用作索引的数据结构,这背后有着深刻的计算机科学原理和实际应用考量。本文将从数据处理与存储服务的角度,解析MySQL选择B+树的核心原因。
一、 索引的核心需求与B+树的特性匹配
数据库索引本质上是一种帮助数据库系统高效检索数据的数据结构。它需要满足几个核心需求:
- 高效的查找效率:支持快速的等值查询和范围查询。
- 适应磁盘I/O特性:磁盘读写速度远慢于内存,因此数据结构应尽量减少磁盘I/O次数(即树的高度要低)。
- 支持高效的插入和删除:在数据动态增删时,能保持结构的平衡,避免性能急剧退化。
- 有序性:便于进行排序和范围扫描。
B+树完美地契合了这些需求:
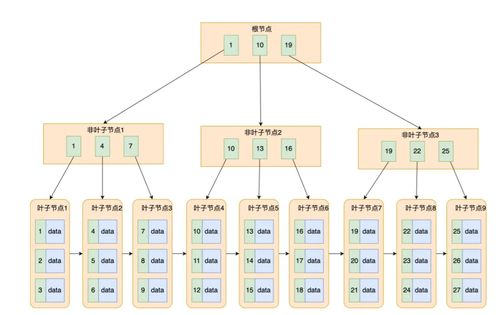
- 多路平衡查找树:B+树是一个多叉树,每个节点可以包含多个键值和指针。这使其拥有更“矮胖”的形态,极大地降低了树的高度。对于一个存储海量数据的索引,树的高度可能仅为3-4层,这意味着查询任何记录最多只需要3-4次磁盘I/O,效率极高。
- 所有数据存储在叶子节点:B+树的所有真实数据记录(或指向记录的指针)都存储在最后一层的叶子节点上,并且叶子节点之间通过指针串联成一个有序链表。这一设计带来了两大核心优势:
- 更稳定的查询效率:任何关键字的查找路径长度都相同,都等于树高,查询性能稳定可预测。
- 卓越的范围查询性能:当进行范围查询(如
WHERE id BETWEEN 100 AND 200)时,只需在叶子节点层找到起始位置,然后顺着链表遍历即可,无需回溯到上层节点,效率极高。
- 内部节点仅存储键值和指针:内部节点(非叶子节点)不存储实际数据行,只存储键值和指向子节点的指针。这使得单个内部节点可以容纳更多的“分支”,进一步降低了树的高度,减少了磁盘I/O。
二、 与B树、哈希表等结构的对比
为了更好地理解B+树的优势,可以将其与其他常见数据结构对比:
- 对比B树:B树(B-Tree)的节点既存储键值也存储对应的数据指针。这意味着数据可能分布在树的任何一层。这在进行范围查询时效率不如B+树,因为B树需要进行中序遍历,可能涉及多次不同层的磁盘访问。而B+树的范围查询集中在连续的叶子节点上,顺序读盘效率高得多。由于B+树内部节点更“精简”,在相同磁盘页大小下能容纳更多的分支因子,树高更低。
- 对比哈希表:哈希表支持O(1)时间复杂度的等值查询,速度极快。但它存在致命缺陷:不支持高效的范围查询和排序,因为哈希函数打乱了数据原有的顺序。哈希索引在数据量增大、发生哈希冲突时,性能可能不稳定。因此,哈希索引在MySQL中通常仅用于某些特定的存储引擎(如MEMORY)或配合B+树索引(如自适应哈希索引)作为补充,无法作为主流索引结构。
- 对比二叉搜索树(如AVL、红黑树):这类树在内存中效率很高,但每个节点最多只有两个分支。当数据量庞大时,树会变得非常高。将这样的高树存储在磁盘上,意味着一次查询可能需要几十甚至上百次磁盘I/O,这是完全无法接受的。B+树通过“多路”特性解决了这个问题。
三、 契合数据处理与存储服务的硬件特性
数据库运行在由内存和磁盘(或SSD)组成的存储体系上。磁盘以“页”(通常为4KB、16KB等)为单位进行读写,每次I/O操作读取一整页数据是最高效的。
B+树的设计充分考虑了这一点:
- 节点大小与磁盘页对齐:数据库系统会将B+树的一个节点大小设置为等于或数倍于磁盘页大小(例如InnoDB默认页大小为16KB)。这样,每次磁盘I/O就能完整地读入一个节点(包含多个键值和指针),极大提升了I/O效率。
- 顺序访问优势:如前所述,B+树叶子节点的链表结构,使得顺序扫描(全表扫描、范围扫描)的性能极佳,这非常符合磁盘顺序读远快于随机读的特性。
四、
MySQL(尤其是其默认存储引擎InnoDB)选择B+树作为索引的底层数据结构,是理论特性与工程实践结合的典范。它通过多路平衡、数据仅存于叶子节点、叶子节点链表化等设计,在减少磁盘I/O次数、稳定查询性能、高效支持范围查询和排序操作等方面取得了最佳平衡。尽管在某些特定场景下(如纯等值查询),哈希索引可能更快,但B+树凭借其全面而均衡的优秀特性,成为了关系型数据库索引事实上的标准解决方案,为现代数据处理和存储服务提供了坚实可靠的基础。
如若转载,请注明出处:http://www.lqcg88.com/product/69.html
更新时间:2026-06-19 17:14:44