构建高效可靠的网络程序 数据处理与存储服务设计指南
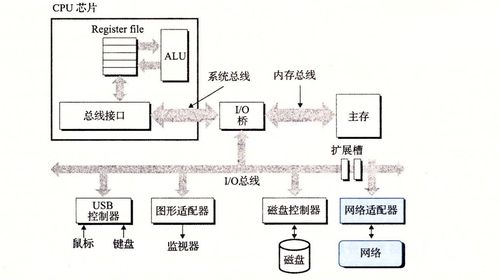
设计一个网络程序的数据处理和存储服务是构建现代应用的核心环节。一个优秀的设计不仅要满足当前业务需求,还应具备良好的可扩展性、可靠性和性能。以下是从架构到实现的关键设计步骤与原则。
一、明确需求与目标
明确服务的核心目标:
- 数据类型与规模:是结构化、半结构化还是非结构化数据?预期数据量及增长速度如何?
- 性能要求:需要低延迟的实时处理,还是高吞吐的批量处理?响应时间和服务可用性目标是多少?
- 一致性需求:需要强一致性、最终一致性,还是允许短暂的数据不一致?
- 安全与合规:数据是否需要加密?有哪些隐私保护或行业法规(如GDPR)需要遵守?
二、架构设计原则
- 解耦与模块化:将数据处理(如清洗、转换、分析)与存储分离,使各模块可以独立开发、部署和扩展。
- 可扩展性:采用水平扩展策略,通过添加节点应对增长的数据负载。微服务架构常被用于此目的。
- 容错与高可用:设计冗余机制,如数据复制、自动故障转移,避免单点故障。
- 弹性与可观测性:集成监控、日志和告警系统,以便快速定位问题并动态调整资源。
三、数据处理层设计
数据处理层负责接收、验证、转换和转发数据。
- 数据接入:通过API(如RESTful、gRPC)、消息队列(如Kafka、RabbitMQ)或事件流接入数据,以缓冲高峰流量并实现异步处理。
- 处理引擎:
- 实时流处理:使用Apache Flink、Apache Storm或Kafka Streams进行连续数据处理。
- 批量处理:使用Apache Spark或Hadoop进行大规模离线计算。
- 数据质量:实施数据验证规则(如格式检查、去重)和错误处理机制(如重试、死信队列)。
四、数据存储层设计
存储层的选择取决于数据特性与访问模式。
- 数据库选型:
- 关系型数据库(如MySQL、PostgreSQL):适合事务性强、结构固定的数据。
- NoSQL数据库:
- 文档数据库(如MongoDB):适合半结构化、嵌套数据。
- 键值存储(如Redis):适合高速缓存与会话数据。
- 列式数据库(如Cassandra):适合时间序列或宽表数据。
- 图数据库(如Neo4j):适合关系密集型数据。
- 存储策略:
- 分层存储:将热数据(频繁访问)放在高速存储(如SSD),冷数据归档至低成本存储(如对象存储S3)。
- 数据分区与分片:按时间、地域或哈希键分割数据,提升查询性能与可扩展性。
- 备份与恢复:定期备份数据,并测试恢复流程以确保数据安全。
五、服务集成与API设计
- 统一接口:提供清晰、版本化的API,便于前端或其他服务调用。使用REST或GraphQL根据查询灵活性需求选择。
- 安全措施:实施身份验证(如OAuth 2.0)、授权(RBAC)和传输加密(TLS),保护数据免受未授权访问。
- 限流与熔断:通过限流(如令牌桶算法)和熔断器(如Hystrix)防止服务过载,提升系统韧性。
六、实施与运维考量
- 容器化与编排:使用Docker封装服务,并通过Kubernetes进行部署、扩展与管理。
- 数据管道编排:采用Apache Airflow或类似工具编排复杂的数据工作流。
- 成本优化:监控资源使用情况,选择按需或预留实例以平衡性能与成本。
七、案例参考
以电商平台订单处理为例:
- 订单数据通过API网关接收,发送至Kafka队列缓冲。
- 流处理服务(Flink)实时验证并计算订单金额,同时将数据写入MySQL(事务记录)和Elasticsearch(搜索索引)。
- 批量作业(Spark)每晚聚合数据,生成销售报表存储于数据仓库(如Snowflake)。
- 所有服务通过Prometheus监控,关键数据备份至S3,确保99.9%的可用性。
设计网络程序的数据处理和存储服务是一个系统工程,需在需求分析基础上,结合合适的架构模式与技术栈,并持续迭代优化。通过关注模块化、可扩展性和可靠性,可以构建出适应业务发展的稳健数据服务。
如若转载,请注明出处:http://www.lqcg88.com/product/72.html
更新时间:2026-06-19 07:54:59