百亿级数据存储架构设计 超越分库分表的系统性解决方案
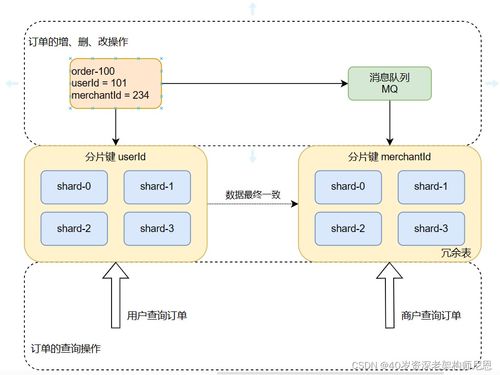
面对百亿级数据的存储挑战,单纯依赖分库分表是远远不够的。它只是解决海量数据存储的基石之一,而一个健壮、可扩展的百亿级数据存储系统需要从数据模型设计、存储架构、数据处理服务和运维保障等多个维度进行系统性设计。
一、 数据存储层的核心设计
分库分表(Sharding)确实是应对数据量膨胀的首要手段,但其设计远非简单拆分。
- 分片策略的精雕细琢:
- 分片键选择:这是最关键的决定,直接影响数据分布的均匀性和查询模式。需要根据核心业务查询(如用户ID、订单ID、时间范围)来选择,并尽量避免跨分片查询。对于时序数据,时间分区常与业务ID哈希结合使用。
- 分片算法:哈希取模能保证均匀,但扩容复杂;范围分片易于扩容和管理,但可能产生热点。实践中常采用一致性哈希或其变种(如带虚拟节点)来平衡分布与扩容的平滑性。
- 分片粒度:是分库、分表,还是库内分表?这需要权衡连接操作、分布式事务的复杂度与单点性能。
- 多级存储与异构架构:
- 热温冷数据分层:百亿数据中访问频率差异巨大。可以采用“在线数据库(如MySQL/分布式NewSQL) + 分析型数据库(如ClickHouse) + 对象存储/归档存储(如S3/HDFS)”的混合架构。热数据保障低延迟读写,温数据支持复杂分析,冷数据低成本归档。
- 索引与存储分离:将主数据与索引分离存储,例如使用Elasticsearch等专门检索引擎处理复杂搜索查询,源数据存储在HBase或Cassandra中。
- 数据库选型与优化:
- 根据一致性要求(CP/AP)选择分布式数据库,如TiDB(强一致)、Cassandra(最终一致)。
- 针对写入密集型场景(如日志、监控),可选用LSM-Tree结构的存储(如HBase, Cassandra),其顺序写入性能优异。
二、 数据处理服务的协同设计
存储之上,必须有高效的数据处理服务来支撑业务。
- 数据写入服务:
- 异步化与批处理:面对海量写入,采用消息队列(如Kafka, Pulsar)作为缓冲层,实现流量削峰和异步解耦。写入服务从队列消费后批量写入存储,大幅提升吞吐量。
- 幂等性与顺序保证:在分布式环境下,通过唯一ID、版本号或事务性消息确保数据的准确性和一致性。
- 数据查询服务:
- 查询路由与聚合:需要中间件(或智能客户端)根据分片键将查询准确路由到对应分片。对于不可避免的跨分片查询(如全量扫描、复杂聚合),设计并行查询框架,在中间件层或使用MPP数据库进行结果汇聚。
- 多级缓存策略:应用层缓存(如Redis集群)热点数据,数据库层缓存查询结果。缓存更新策略(如旁路缓存、写穿透)需精心设计以保持数据新鲜度。
- 读写分离与负载均衡:为读多写少的场景配置从库,通过代理或客户端实现读写分离,减轻主库压力。
- 数据处理流水线:
- 构建实时与离线两套数据处理链路。实时流使用Flink/Spark Streaming进行实时统计、风控;离线数仓使用Hive/Spark进行T+1的深度分析与报表生成。
- 数据湖与数据仓库:将原始数据以低成本格式(如Parquet)存入数据湖(如HDFS/S3),再按主题导入数仓,支持灵活的即席查询与机器学习。
三、 保障体系的构建
- 可观测性与监控:建立完善的指标监控(QPS、延迟、错误率)、链路追踪和日志体系,快速定位瓶颈与故障。
- 弹性伸缩与自动化运维:存储与计算资源应能根据负载自动伸缩。利用Kubernetes等容器编排技术管理无状态服务,并实现分片迁移、集群扩缩容的自动化。
- 数据备份与容灾:跨机房、跨地域的数据备份与容灾方案必不可少。采用多副本机制保障高可用,定期全量备份加实时增量备份确保数据可恢复。
百亿级数据存储的设计是一个复杂的系统工程。分库分表解决了数据分布的“分治”问题,但必须与精心的数据模型设计、异构的存储选型、高效的数据处理服务层以及强大的运维保障体系紧密结合,才能构建出既稳定可靠又灵活高效的大数据存储平台。它考验的是架构师对数据生命周期、业务访问模式和技术栈特性的全局把握与深度整合能力。
如若转载,请注明出处:http://www.lqcg88.com/product/83.html
更新时间:2026-06-19 01:28:18