数据湖存储格式Hudi 核心原理与实践应用
随着大数据时代的深入发展,企业对数据处理的实时性、一致性和管理效率提出了更高要求。传统的数仓架构与原始数据湖方案在处理更新删除、增量消费、实时分析等场景时面临挑战。Apache Hudi(Hadoop Upserts Deletes and Incrementals)应运而生,作为一种开源的数据湖存储格式,它通过在HDFS或云存储之上引入表、事务、高效索引等数据库核心概念,为大数据处理与存储服务带来了革新。
一、Hudi的核心原理
Hudi的设计核心在于将存储层(如HDFS)上的数据集组织成具有ACID事务支持的时间线(Timeline)管理的表,并提供了两种基础存储类型:
- Copy-on-Write (COW) 表:
- 原理:在数据写入时(无论是插入、更新还是删除),Hudi会直接创建包含所有受影响记录的新版本数据文件(Parquet格式),并同步更新元数据索引。查询引擎始终读取最新版本的文件。
- 特点:写时合并,读取性能高(直接读最新文件),但写入延迟较高且存在写放大问题。适用于读多写少、对查询延迟敏感的场景。
- Merge-on-Read (MOR) 表:
- 原理:将更新/删除操作记录到增量日志文件(Avro格式)中,并与基础列式文件(Parquet格式)并存。在读取时(或根据策略异步压缩时),实时或异步地将增量日志与基础文件合并,生成新的列式文件。
- 特点:读时合并,写入延迟低(只需写增量日志),但读取时需要合并,查询延迟相对较高。适用于写多读少、对写入延迟敏感且需要近实时分析的场景。
核心机制:
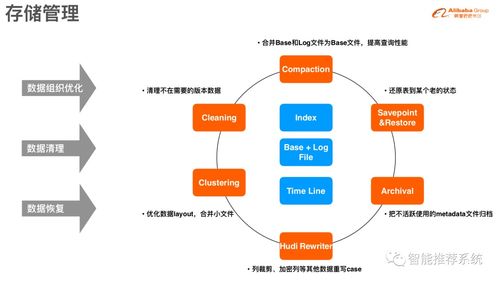
时间线 (Timeline):记录所有对数据集的操作(提交、清理、压缩等)及其状态,是保证ACID语义和实现时间旅行查询的基础。
索引 (Index):Hudi提供了多种索引(如布隆过滤器索引、HBase索引等),用于快速定位一条记录存在于哪个文件,从而实现高效的Upsert和Delete,避免全表扫描。
* 表类型 & 查询类型:结合COW/MOR表类型与快照查询(读取最新合并数据)、增量查询(读取某个提交后新增的变更数据)、读优化查询(仅读取MOR表的基础列式文件)等多种查询模式,为不同场景提供灵活的数据访问视角。
二、Hudi在数据处理与存储服务中的实践
Hudi的价值在于它不仅仅是存储格式,更是一套数据管理服务框架,能够无缝集成Spark、Flink、Presto/Trino、Hive等主流计算查询引擎。
1. 核心数据处理场景实践:
高效的增量ETL管道:利用Hudi的增量查询功能,可以轻松捕获自上次处理以来的变更记录,仅处理增量数据而非全量表,极大提升ETL效率,降低计算与IO成本。
近实时数据摄取与更新:通过Flink或Spark Streaming将Kafka等流式数据以Upsert方式写入Hudi MOR表,可实现分钟甚至秒级的延迟,并支持对历史记录的更新修正。
变更数据捕获与同步:将数据库的CDC数据直接写入Hudi,构建一个支持更新删除的实时数据湖镜像,便于下游消费和分析。
数据回溯与时间旅行:基于时间线,可以轻松查询数据在历史任意时间点的快照状态,满足审计、故障排查、实验回滚等需求。
2. 数据存储与管理优化实践:
自动文件管理:Hudi自动处理小文件合并(压缩),优化文件大小和数量,提升查询性能。同时提供清理(Clean)功能,删除不再需要的旧文件版本,控制存储成本。
统一批流存储层:Hudi表可以同时作为批处理和流处理作业的源与目标,实现了批流存储的统一,简化了Lambda架构的复杂性,助力向Kappa架构演进。
* 数据治理与合规:通过元数据管理、事务保障和数据生命周期策略(保留、清理),为数据湖提供更好的治理能力,满足合规性要求。
三、最佳实践与考量
在实践中,成功部署Hudi需考虑以下几点:
- 表类型选择:根据读写模式(写频率、读频率、延迟要求)谨慎选择COW或MOR。
- 索引选择:根据数据规模和Upsert模式选择合适索引,平衡写入开销与查询性能。
- 资源配置与调优:合理设置压缩(Compaction)、清理(Cleaning)策略的调度间隔和并行度,调整文件大小目标。
- 与现有生态集成:确保计算引擎(Spark/Flink版本)与Hudi版本的兼容性,并正确配置Catalog(如Hive Metastore)以支持多引擎查询。
****
Apache Hudi通过将数据库的事务、索引、高效更新等特性引入数据湖存储层,有效解决了大数据场景下的增量处理、近实时更新和数据管理难题。它不仅是存储格式的创新,更是构建高效、可靠、易管理的数据湖平台的关键服务组件。随着云原生和实时分析需求的增长,深入理解Hudi原理并善用其最佳实践,将成为构建现代化数据处理与存储服务体系的核心竞争力。
如若转载,请注明出处:http://www.lqcg88.com/product/84.html
更新时间:2026-06-19 08:18:42