Facebook图形数据库Tao 揭秘数据处理与存储的革新之路
在当今数据爆炸的时代,传统关系型数据库因其固定的表结构和复杂的关系映射,在处理海量、高度关联的社交网络数据时常常显得力不从心。Facebook作为全球最大的社交平台,每天需要处理数以千亿计的查询和更新操作,其核心数据模型——用户、页面、照片、评论及其之间错综复杂的“点赞”、“关注”、“分享”关系——本质上是一个巨大的图。为了应对这一挑战,Facebook设计并开发了名为“Tao”的分布式图形数据库系统,它专为处理海量社交图谱数据而生,深刻挑战了传统关系型数据库的统治地位。
一、Tao的诞生背景与核心目标
传统关系型数据库(如MySQL)在Facebook早期发挥了重要作用。随着用户量和数据关系的指数级增长,其局限性日益凸显:多表关联查询性能低下、难以水平扩展、模式变更成本高昂。社交图谱数据是典型的图数据,查询模式往往围绕实体(节点)和关系(边)展开,例如“查找某个用户的所有朋友”或“查找两张照片的共同点赞者”。这些操作在图数据库中可以被高效地建模为图的遍历,而在关系型数据库中则需要多次的表连接,效率低下。
Tao的核心目标非常明确:为Facebook的社交图谱数据提供一个高吞吐、低延迟、强最终一致性且能实现全球规模扩展的数据访问层。它不是一个通用的数据库,而是一个高度定制化、针对“读多写少”的社交图谱访问模式进行深度优化的专用系统。
二、Tao的架构揭秘:分层设计与数据模型
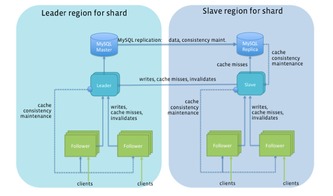
Tao采用经典的分层架构,将逻辑与物理存储分离:
- 客户端层与缓存层:这是Tao性能的关键。每个数据中心的Tao系统都包含一个庞大的多层缓存结构。前端服务器上的Tao客户端库会首先查询本地内存缓存,如果未命中,则请求该数据中心的Tao缓存服务器。缓存中存储了最热门的对象(节点)和关联列表(边)。这种设计使得绝大多数读取请求(超过99%)根本无需触及后端数据库,从而实现了惊人的低延迟和高吞吐。
- 持久化存储层:缓存的后端是持久化存储,Facebook选择了经过深度修改的MySQL作为“源 of truth”。数据被分片存储在许多MySQL实例中。Tao的数据模型极其简洁:
- 对象(Objects):即图的节点,如用户、页面、照片。每个对象有唯一的ID、类型和一组属性(键值对)。
* 关联(Associations):即图的边,如“用户A是用户B的朋友”。每条边由源对象ID、目标对象ID、关联类型和一个时间戳/属性数据组成。
所有对象和关联都作为简单的行存储在MySQL表中,通过精心设计的主键和索引来优化访问。
- 领导者-追随者模型与地理分布:为了支持全球用户,Tao将数据主副本(领导者)部署在一个主数据中心,并在多个从数据中心(追随者)维护只读副本。写入操作被发送到主数据中心,然后异步复制到从数据中心。这种设计牺牲了跨数据中心的强一致性,换来了地理上近距离读取的低延迟,符合“写一次,读多处”的社交模式。
三、对传统数据处理与存储范式的挑战与革新
- 从关系建模到图建模:Tao将数据建模为首要的“图”,而不是强行拆分为表和关系。这使得表达和查询复杂关系变得直观且高效,直接满足了社交应用的核心需求。
- 读写路径的极端优化:通过将缓存作为系统的核心,而非数据库的附加组件,Tao将读取路径优化到了极致。它承认了社交数据访问的高度局部性(少数热门内容被频繁访问),并基于此构建了整个系统。
- 一致性权衡的艺术:Tao明确选择了最终一致性模型。在跨数据中心的场景下,用户可能短暂看到过时数据(如刚发布的评论稍后才在另一个地区显示),但这对于社交体验来说是可接受的。这种权衡使得系统能够实现全球规模的扩展和高可用性。
- 专用化而非通用化:Tao证明了在超大规模场景下,针对特定工作负载定制数据存储比使用通用解决方案更有效。它不做复杂的SQL查询,不支持跨分片事务,只提供针对图的原子操作(如
assoc<em>add,assoc</em>get),从而实现了极致的简化和性能。
四、影响与启示
Tao的成功运行(高峰期每秒处理数十亿次查询)不仅支撑了Facebook的核心业务,也为整个行业处理图数据提供了宝贵范式。它启示我们:
- 在面对特定领域的海量数据时,可以且应该设计领域专用的存储系统。
- 缓存是提升大规模系统性能的利器,可以提升到架构的核心地位。
- 在可扩展性、性能和一致性之间做出明智的权衡是分布式系统设计的关键。
虽然Tao是Facebook内部系统,但其设计理念深刻影响了后续许多开源图形数据库(如JanusGraph、Nebula Graph)和商业服务的发展。它标志着数据处理与存储服务从“一刀切”的关系型模型,向着多样化、场景化、深度优化的新时代迈进。在图形数据日益重要的今天,Tao的揭秘为我们理解如何构建下一代数据基础设施提供了至关重要的蓝图。
如若转载,请注明出处:http://www.lqcg88.com/product/63.html
更新时间:2026-06-19 13:41:11